假设我们有两个机器 A 与 B,其中 A 和 B 在各自的局域网中的网段分别是 192.168.2.0/24 和 192.168.3.0/24。A 和 B 都接入了一个 VPN 网络,其内网地址是 10.0.0.0/16。那么,如何让 A 访问 B 所在局域网内的另一台机器 C 呢?注意 C 是没有接入到 VPN 私有网络的。一个办法是直接让 C 也接入到 VPN 网络中,但是如果 B 的局域网中有众多设备需要被 A 访问时,将这些节点都加入 VPN 网络配置会非常麻烦。在一些场景下,VPN 的连接数量有限制(例如 Zerotier)。因此我们需要新的方案。这篇文章我们介绍通过巧妙地配置路由表和防火墙来实现。
我们假定 A 的地址是 192.168.2.2/24 和 10.0.0.2/16,B的地址是 192.168.3.2/24 和 10.0.0.3/16,C 的地址是 192.168.3.3/24。我们这里介绍的是让 A 访问 B 所在的子网。反过来让 B访问 A的子网的设置方法是类似的。进行双向设置以后就可以实现完整的 Site-to-Site 组网。这里我们假设 A 和 B 都安装了 Ubuntu 操作系统。
2 路由配置
首先我们需要进行路由表的配置,让 A 知道应该以 B 为网关来来访问 192.168.3.0/24 子网。在 A 上运行
完成路由配置之后,A 机器能够知道到达 192.168.3.0/24 子网的路由路径,但是此时让 A 直接访问 C 的地址会失败,因为他们之间的通信会被 B 的防火墙拦截。因此我们需要对防火墙进行进一步配置。防火墙的配置分为两个主要的步骤:首先我们需要允许经过 B进行路由的数据包经过防火墙。在 B 上运行下面的代码:
注意其中的 -i-o 指定的接口名称需要针对你的服务器的实际情况调整。这里我们进行的往返路由路径的分别配置,将路由策略都设置为 ACCEPT 使得数据包能够通过 B 的防火墙。
对防火墙进行配置的第二个步骤是在 B 上开启地址伪装,即 MASQUERADE 机制。注意到我们在 A 上配置了路由表,但是没有作为访问目标的 C 则并不知道通向 A 的路由路径(A 和 B 之间在的 VPN 私有网络中是直通的,不需要额外路由)。因此我们需要配置进行一个额外的配置,即在 B 中开启地址伪装,此时 B 会将来自 A 的,以 C 为目标的数据包的源地址修改为自身的地址,那么 C 会认为这个包来自 B,响应也会被发送给 B,B 再将包转发回到 A。要开启地址伪装,需要在 B 上开启 iptables 配置:
SAT 代表“分离轴定理”(Separating Axis Theorem),这是计算机图形学和物理引擎中用于检测两个凸多边形之间是否存在重叠(即碰撞检测)的一个重要方法。根据这个定理,如果能找到一个轴(分离轴),使得将两个多边形在这个轴上的投影完全分开,那么这两个多边形就不相交;反之,如果对于所有可能的分离轴,两个多边形的投影都重叠,则两个多边形相交。这个定理简化了复杂形状之间碰撞检测的计算,使得它成为实现高效碰撞检测算法的关键。
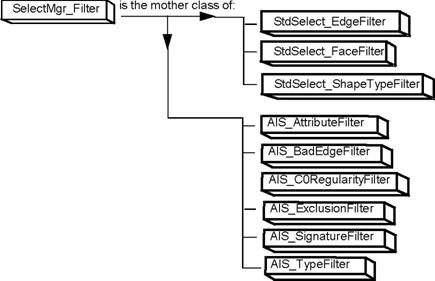
SelectMgr_BaseFrustum, SelectMgr_Frustum, SelectMgr_RectangularFrustum, SelectMgr_TriangularFrustum and SelectMgr_TriangularFrustumSet - 这些类和皆苦与选择视锥有关,他们定义了不同的 SAT 测试方法,同时也包含了计算定量特质数值的方法(例如计算深度和距离)
SelectMgr_SensitiveEntity, SelectMgr_Selection and SelectMgr_SensitiveEntitySet - 存储和处理敏感实体的数据,SelectMgr_SensitiveEntitySet 实现了第二级 BVH 树的元素集合;
SelectMgr_SelectableObject and SelectMgr_SelectableObjectSet - 描述了可选择对象。它们也负责存储,计算和移除选择数据。SelectMgr_SelectableObjectSet 提供了第一级 BVH 树的实现;
// Suppose there is an instance of class InteractiveBox from the previous sample. // It contains an implementation of method InteractiveBox::ComputeSelection() for selection // modes 0 (whole box must be selected) and 1 (edge of the box must be selectable) Handle(InteractiveBox) theBox; Handle(AIS_InteractiveContext) theContext; // To prevent automatic activation of the default selection mode theContext->SetAutoActivateSelection (false); theContext->Display (theBox, false); // Load a box to the selection manager without computation of any selection mode theContext->Load (theBox, -1, true); // Activate edge selection theContext->Activate (theBox, 1); // Run the detection mechanism for activated entities in the current mouse coordinates and in the current view. // Detected owners will be highlighted with context highlight color theContext->MoveTo (aXMousePos, aYMousePos, myView, false); // Select the detected owners theContext->Select(); // Iterate through the selected owners for (theContext->InitSelected(); theContext->MoreSelected() && !aHasSelected; theContext->NextSelected()) { Handle(AIS_InteractiveObject) anIO = theContext->SelectedInteractive(); } // deactivate all selection modes for aBox1 theContext->Deactivate (aBox1);
另外需要提及的一个重点是,OCCT 的矩形选择支持两种探测模式:
包含(Inclusive):只有目标完全包含在选择视锥内部时才会被认为是被选中的;
覆盖(Overlap):只要目标与选择视锥存在交集就认为选中。
默认情况下 OCCT 会使用第一种,要修改这个默认行为,可以使用下面的方法:
1 2 3 4 5 6
// Assume there is a created interactive context constHandle(AIS_InteractiveContext) theContext; // Retrieve the current viewer selector constHandle(StdSelect_ViewerSelector3d)& aMainSelector = theContext->MainSelector(); // Set the flag to allow overlap detection aMainSelector->AllowOverlapDetection (true);
for (myAISCtx->InitSelected(); myAISCtx->MoreSelected(); myAISCtx->NextSelected()) { Handle(SelectMgr_EntityOwner) anOwner = myAISCtx->SelectedOwner(); Handle(AIS_InteractiveObject) anObj = Handle(AIS_InteractiveObject)::DownCast (anOwner->Selectable()); if (Handle(StdSelect_BRepOwner) aBRepOwner = Handle(StdSelect_BRepOwner)::DownCast (anOwner)) { // to be able to use the picked shape TopoDS_Shape aShape = aBRepOwner->Shape(); } }
AIS_ColoredShape aColoredShape = newAIS_ColoredShape (theShape); // setup color of entire shape aColoredShape->SetColor (Quantity_NOC_RED); // setup line width of entire shape aColoredShape->SetWidth (1.0); // set transparency value aColoredShape->SetTransparency (0.5); // customize color of specified sub-shape aColoredShape->SetCustomColor (theSubShape, Quantity_NOC_BLUE1); // customize line width of specified sub-shape aColoredShape->SetCustomWidth (theSubShape, 0.25);
MeshVS_SMF_0D MeshVS_SMF_Link MeshVS_SMF_Face MeshVS_SMF_Volume MeshVS_SMF_Element // groups 0D, Link, Face and Volume as a bit mask; MeshVS_SMF_Node MeshVS_SMF_All // groups Element and Node as a bit mask; MeshVS_SMF_Mesh MeshVS_SMF_Group
例如下面的对象,可以并用来显示 STL 文件格式的对象:
1 2 3 4 5 6 7 8 9 10 11
// read the data and create a data source Handle(Poly_Triangulation) aSTLMesh = RWStl::ReadFile (aFileName); Handle(XSDRAWSTLVRML_DataSource) aDataSource = newXSDRAWSTLVRML_DataSource (aSTLMesh); // create mesh Handle(MeshVS_Mesh) aMeshPrs = newMeshVS(); aMeshPrs->SetDataSource (aDataSource); // use default presentation builder Handle(MeshVS_MeshPrsBuilder) aBuilder = newMeshVS_MeshPrsBuilder (aMeshPrs); aMeshPrs->AddBuilder (aBuilder, true);
// assign nodal builder to the mesh Handle(MeshVS_NodalColorPrsBuilder) aBuilder = newMeshVS_NodalColorPrsBuilder (theMeshPrs, MeshVS_DMF_NodalColorDataPrs | MeshVS_DMF_OCCMask); aBuilder->UseTexture (true); // prepare color map Aspect_SequenceOfColor aColorMap; aColorMap.Append (Quantity_NOC_RED); aColorMap.Append (Quantity_NOC_BLUE1); // assign color scale map values (0..1) to nodes TColStd_DataMapOfIntegerReal aScaleMap; ... // iterate through the nodes and add an node id and an appropriate value to the map aScaleMap.Bind (anId, aValue); // pass color map and color scale values to the builder aBuilder->SetColorMap (aColorMap); aBuilder->SetInvalidColor (Quantity_NOC_BLACK); aBuilder->SetTextureCoords (aScaleMap); aMesh->AddBuilder (aBuilder, true);
// get the group Handle(Graphic3d_Group) aGroup = thePrs->NewGroup(); // change the text aspect Handle(Graphic3d_AspectText3d) aTextAspect = newGraphic3d_AspectText3d(); aTextAspect->SetTextZoomable (true); aTextAspect->SetTextAngle (45.0); aGroup->SetPrimitivesAspect (aTextAspect); // add a text primitive to the structure Handle(Graphic3d_Text) aText = newGraphic3d_Text (16.0f); aText->SetText ("Text"); aText->SetPosition (gp_Pnt (1, 1, 1)); aGroup->AddText (aText);
// create a default display connection Handle(Aspect_DisplayConnection) aDispConnection = newAspect_DisplayConnection(); // create a Graphic Driver Handle(OpenGl_GraphicDriver) aGraphicDriver = newOpenGl_GraphicDriver (aDispConnection); // create a Viewer to this Driver Handle(V3d_Viewer) aViewer = newV3d_Viewer (aGraphicDriver); aViewer->SetDefaultBackgroundColor (Quantity_NOC_DARKVIOLET); // Create a structure in this Viewer Handle(Graphic3d_Structure) aStruct = newGraphic3d_Structure (aViewer->StructureManager()); aStruct->SetVisual (Graphic3d_TOS_SHADING); // Type of structure // Create a group of primitives in this structure Handle(Graphic3d_Group) aPrsGroup = aStruct->NewGroup(); // Fill this group with one quad of size 100 Handle(Graphic3d_ArrayOfTriangleStrips) aTriangles = newGraphic3d_ArrayOfTriangleStrips (4); aTriangles->AddVertex (-100./2., -100./2., 0.0); aTriangles->AddVertex (-100./2., 100./2., 0.0); aTriangles->AddVertex ( 100./2., -100./2., 0.0); aTriangles->AddVertex ( 100./2., 100./2., 0.0); Handle(Graphic3d_AspectFillArea3d) anAspects = newGraphic3d_AspectFillArea3d (Aspect_IS_SOLID, Quantity_NOC_RED, Quantity_NOC_RED, Aspect_TOL_SOLID, 1.0f, Graphic3d_NameOfMaterial_Gold, Graphic3d_NameOfMaterial_Gold); aPrsGroup->SetGroupPrimitivesAspect (anAspects); aPrsGroup->AddPrimitiveArray (aTriangles); // Create Ambient and Infinite Lights in this Viewer Handle(V3d_AmbientLight) aLight1 = newV3d_AmbientLight (Quantity_NOC_GRAY50); Handle(V3d_DirectionalLight) aLight2 = newV3d_DirectionalLight (V3d_Zneg, Quantity_NOC_WHITE, true); aViewer->AddLight (aLight1); aViewer->AddLight (aLight2); aViewer->SetLightOn(); // Create a 3D quality Window with the same DisplayConnection Handle(Xw_Window) aWindow = newXw_Window (aDispConnection, "Test V3d", 100, 100, 500, 500); aWindow->Map(); // Map this Window to this screen // Create a Perspective View in this Viewer Handle(V3d_View) aView = newV3d_View (aViewer); aView->Camera()->SetProjectionType (Graphic3d_Camera::Projection_Perspective); // Associate this View with the Window aView->SetWindow (aWindow); // Display presentation in this View aStruct->Display(); // Finally update the Visualization in this View aView->Update(); // Fit view to object size aView->FitAll();
本文的作者通过引入图卷积神经网络 (GCN) 来解决 Symbol Spotting 问题。GCN 网络可以给出每个图元的语义信息,同时还有一个 CNN 网络来给出“可数”构件的实例分割结果。
1.2 Transformer 的作用
基于 Transformer,可以在不预先定义图连接结构的情况下,基于注意力机制推断到 tokens 之间的全局关系 (Transformers reason global relationships across tokens without pre-defined graph connectivity, by instead learning with self-attention)。这使得 Transformer 可以在 panoptic symbol spotting 任务中替代 GCN 的作用。但是标准的 Transformer 在这类任务上的使用仍然存在一些挑战:
Tokenization and position encoding of graph symbols:前者是编码的问题,后者则是典型的 ViT 引入的问题。典型的 ViT,即 Visual Transformer 会将每个图像划分成 14×14 或者 16×16 个 Patch,即 token,同时基于这个二维网格分布可以将这些 token 的顺序线性化,并组合在一起。不过在 CAD 数据中,图元数据的排列是无序的,且坐标数值属于连续的实数空间,并非离散化,这和栅格化的图像有根本性的不同。
Inmense set of primitives in certain scenes. ViT 的全局注意力机制的复杂度相比于 token 的数量是四次方的,如果是处理 CAD 数据,由于图元的数量非常庞大,这个数量级的复杂度是无法处理的。
Training data limitations. ViT 架构能够提供更多灵活性的同时,其对数据的需求量也更大了。
作者提出的 CADTransformer 旨在成为一个通用的框架,可以被轻易地和现有的 ViT 骨干网络整合起来。
CADTransformer 是作为一个完整的 ViT 处理 Pipe 的一部分被插入到图像处理流程中。
]]><p>这次要读的文章是 <a href="https://openaccess.thecvf.com/content/CVPR2022/papers/Fan_CADTransformer_Panoptic_Symbol_Spotting_Transformer_for_CAD_Drawings_CVPR_2022_paper.pdf">CADTransformer: Panoptic Symbol Spotting Transformer for CAD Drawings</a></p>
<p>这篇论文介绍了一个名为CADTransformer的新框架,用于自动化CAD图纸中的全景符号识别任务。该任务需要识别和解析可数对象实例(如窗户、门、桌子等)和不可数的物品(如墙壁、栏杆等),并在CAD图纸中进行标记。该任务的主要难点在于图纸中符号的高度不规则的排序和方向。现有方法基于卷积神经网络(CNNs)和/或图神经网络(GNNs)来回归实例边界框并将预测结果转换为符号。相比之下,CADTransformer直接从CAD图形原始集合中进行标记,通过一对预测头同时优化线条级别的语义和实例符号识别。此外,该框架还通过几个可插拔的修改增强了主干网络,包括邻域感知自注意力、分层特征聚合和图形实体位置编码等。此外,该论文还提出了一种新的数据增强方法,称为随机层(Random Layer),通过CAD图纸的分层分离和重组来进行数据增强。最终,CADTransformer在最新发布的FloorPlanCAD数据集上,将先前的最先进水平从0.595提高到0.685,展示了该模型可以识别具有不规则形状和任意方向的符号。</p>解决在 Openvpn 客户端中部署的 Web 服务不可用的问题https://www.codewoody.com/posts/41015/2023-04-04T09:32:20.000Z2023-04-05T16:12:12.047Z遇到这样一个蛋疼的问题,我有一台服务器,上面部署了一个 web 服务,同时我也想把这个服务器作为客户端连入一个 OpenVPN 虚拟网络,并且我希望服务器上的程序能够通过 OpenVPN 的网关来访问外部网络,这主要是为了隐藏服务器的身份。但是在 OpenVPN 连接之后,原有的 Web 服务将无法访问。通过调试分析可以法线,造成这一现象的原因是 Web 服务的响应包也被路由配置路由到 OpenVPN 的 tun0 接口中。这导致响应无法返回给原来的请求服务器。如何解决这个问题呢?
如果你在网络上搜索这类问题你会发现各种文章给出的方案一般都是为 OpenVPN 的配置文件添加 route-nopull 选项来阻止 OpenVPN 设置客户端路由,但是这会导致客户端的对外访问无法通过 VPN 进行。事实上,从 IP 路由的角度来看,如果我的服务器是 A,而某个访问 Web 服务的 IP 是 B,同时 B 也可能是 A 试图访问的外部的目标服务提供者。对传输层路由而言,A 给 B 的 Web 服务响应和 A 主动发往 B 的请求是无法区分的。从这个角度来看,要达成 inbound 和 outbound 流量分别路由似乎是不可能的。
但是其实我们有一个突破点:那就是 Web 服务总是在本机使用固定的端口和请求者通信,我们可以通过端口来区分 inbound 和 outbound 流量。首先我们输入下面的命令:
1
iptables -t mangle -A OUTPUT -p tcp -m multiport --sports 80,443 -j MARK --set-mark 1
]]><div class="note danger">
<p>update at 2023.4.27:</p>
<p>Github 上有人做了一个开源的油猴脚本 <a href="https://github.com/xcanwin/KeepChatGPT">KeepChatGPT<读论文: 基于图卷积网络实现的三维室内场景构建https://www.codewoody.com/posts/30599/2023-02-23T09:24:45.000Z2023-03-23T10:02:23.744Z这次阅读的论文是 SceneHGN: Hierarchical Graph Networks for 3D Indoor Scene Generation with Fine-Grained Geometry,这是今年(2023)年发表在 IEEE Transactions on Pattern Analysis and Machine Intelligence 期刊上的文章,作者来自中科院。
当然,这种统筹方法会存在很多挑战。一个房间内的各个要素构成了一个天然的垂直层级结构:房间内包含多个家具对象,每个家具对象也可以由多个灵活子组件构成。房间内的对象数量可能很多(3D FRONT 数据集中的一个房间最多可以包含 188 个对象),这使得学习会比较困难。考虑到在大型房间中,部分对象之间内部会存在一定的关联(例如若干个椅子围绕着一个桌子摆放),作者引入了 Function Regions 的概念,如用餐区,沙发区等。功能区概念作为一个中间层在房间与具体的对象之间,作为一个衔接桥梁。
作者提出的网络架构包括一个房屋布局编码器(room layout encoder),一个场景层次结构编码器(scene hierachy encoder)以及一个场景层次结构解码器(scene heirachy decoder)。其中房间布局编码器以房间边界的分解梯度表示(deformation gradients of the floor boundary)作为输入条件,并提取处一个向量。此向量被用于解码器的输入条件。场景分层编码器完成了从房间级别逐级向下到功能区级别,对象级别并最终到对象组件几何级别,逐层地、递归地将房间多层体系映射到的通用隐藏空间(类似神经网络的隐藏层?)中(这句话很难翻译,原文是 The scene hierarchy encoder maps the indoor scene hierarchies from the room level to the functional region level, the object level, and finally down to the object part geometry level into a common space hierarchically and recursively),解码器的作用正好相反。
对于二元关系边的预测,我们对于任意两两节点组合,结合其特征判断每种边的存在概率。对于多元关系,我们通过注意力机制来预测一个 mask, Mi 来表示哪些节点共享了一个多元边属性。利用节点之间的边连接关系,我们执行两轮消息传递过程来更新节点特征。最终得到的节点特征为:{fNj1,fNj2,⋯,fNki},其中 ki 表示每个父节点 Ni 的子节点。综上,我们有
其中 Ci 是 Oi 的倾转 bbox 的中点,p=1N∑Ni=1Ci 是所有相关对象的中点组成的点集的中点,v=norm(∑Ni=1∑Nj=i+1(Cj−Ci)) 所有相关对象的平均相对位置。norm 表示将向量长度单元化。在计算 v 时,我们将对象中点的在水平面上的横纵坐标按照升序排序,从而避免相反向量被抵消。最终的损失函数是:
]]><p>这次阅读的论文是 <a href="https://ieeexplore.ieee.org/document/10018465/">SceneHGN: Hierarchical Graph Networks for 3D Indoor Scene Generation with Fine-Grained Geometry</a>,这是今年(2023)年发表在 IEEE Transactions on Pattern Analysis and Machine Intelligence 期刊上的文章,作者来自中科院。</p>BIM 中的几何表达方式https://www.codewoody.com/posts/1531/2023-02-17T08:31:54.000Z2023-02-20T07:05:23.081Z三维几何表示时 BIM 模型的重要基础。这篇文章主要阐述 BIM 中几何模型设计原则与基本思想。